System Architecture¶
High-Level Architecture¶
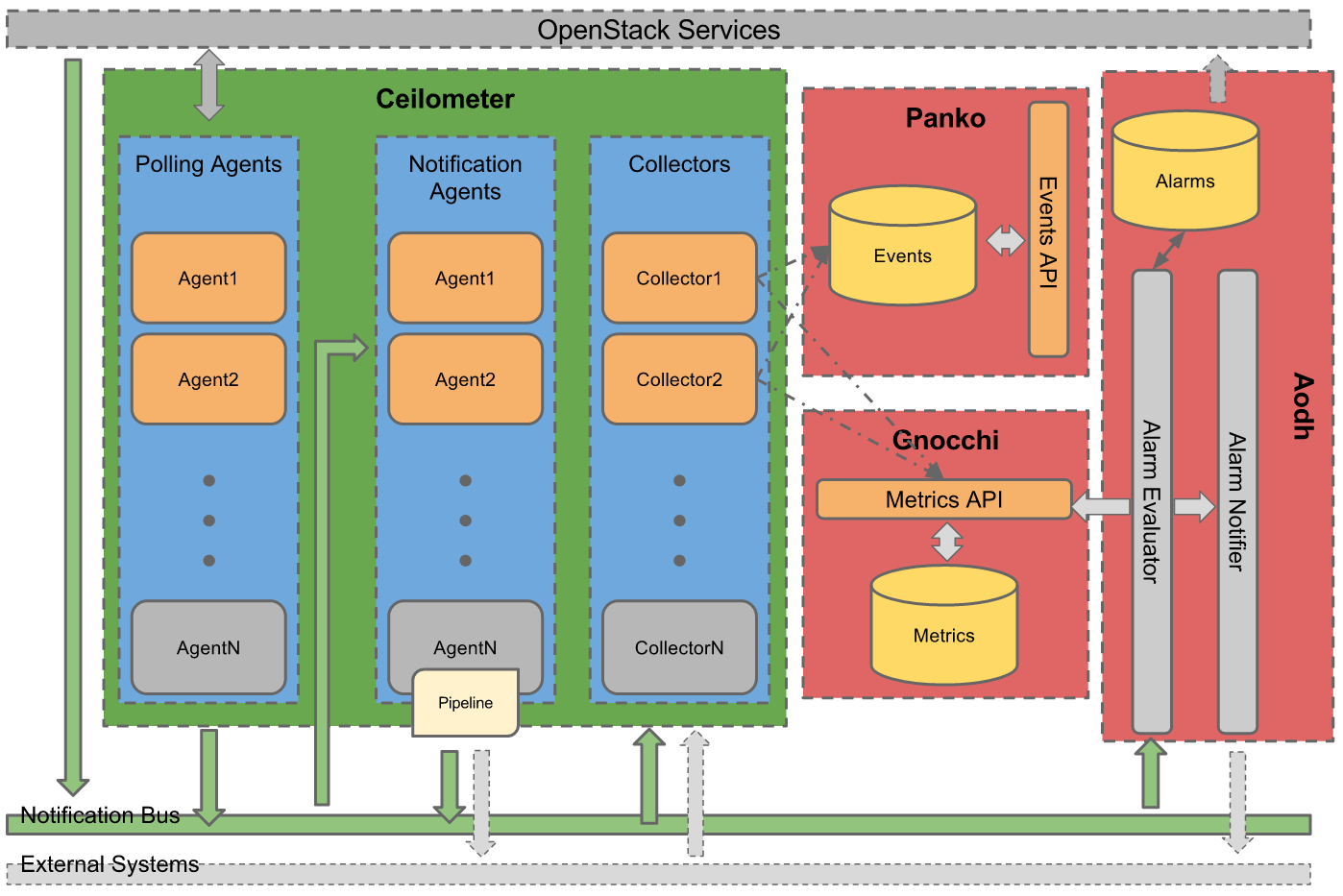
An overall summary of Ceilometer’s logical architecture.
Each of Ceilometer’s services are designed to scale horizontally. Additional workers and nodes can be added depending on the expected load. Ceilometer offers three core services, the data agents designed to work independently from collection, but also designed to work together as a complete solution:
- polling agent - daemon designed to poll OpenStack services and build Meters.
- notification agent - daemon designed to listen to notifications on message queue, convert them to Events and Samples, and apply pipeline actions.
- (optional) collector - daemon designed to gather and record event and metering data created by notification and polling agents (if using Gnocchi or full-fidelity storage).
- (optional) api - service to query and view data recorded by collector in internal full-fidelity database (if enabled).
Data normalised and collected by Ceilometer can be sent to various targets. Gnocchi was developed to capture measurement data in a time series database to optimise storage and querying. Gnocchi is intended to replace the existing metering database interface. Additionally, Aodh is the alarming service which can be send notifications when user defined rules are broken. Lastly, Panko is the event storage project designed to capture document-oriented data such as logs and system event actions.
Gathering the data¶
How is data collected?¶
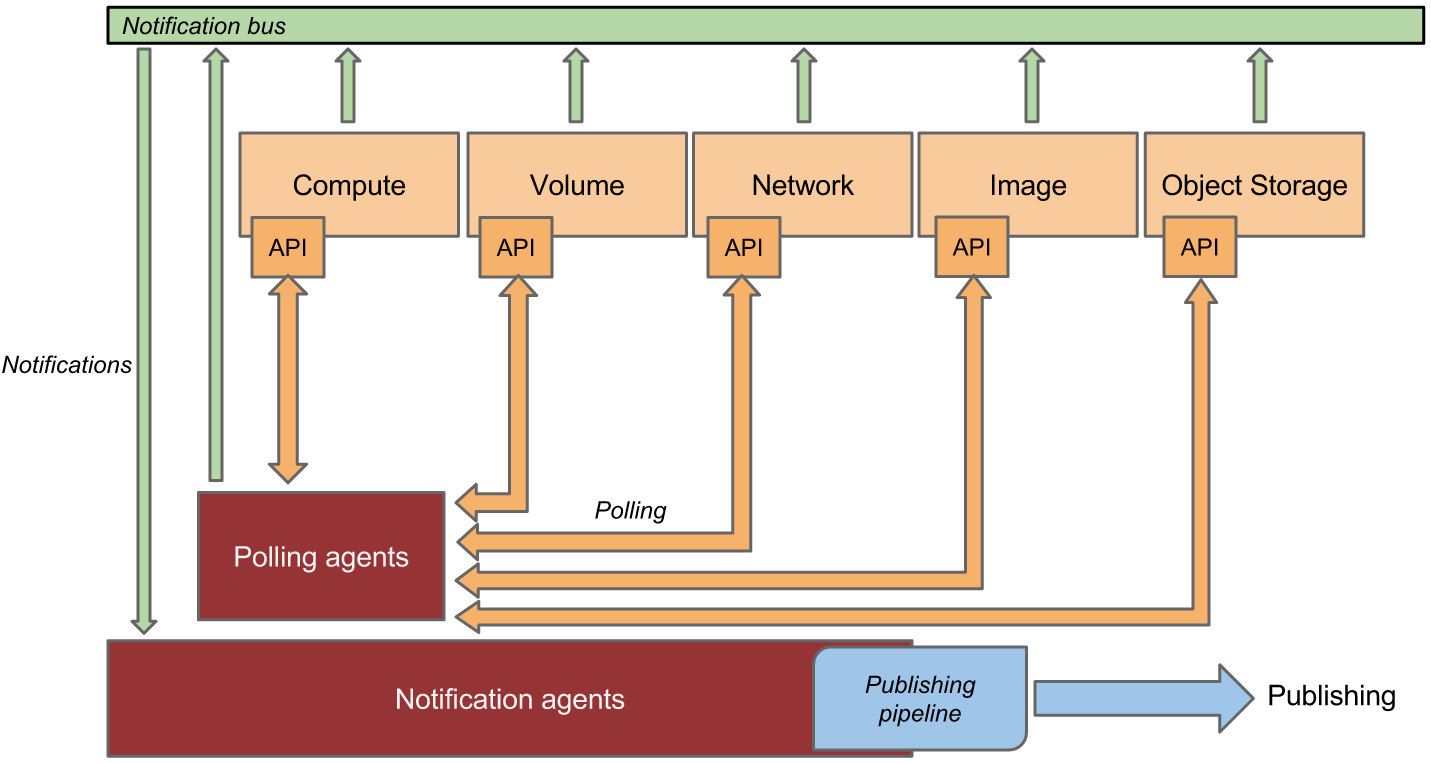
This is a representation of how the collectors and agents gather data from multiple sources.
The Ceilometer project created 2 methods to collect data:
- Bus listener agent which takes events generated on the notification bus and transforms them into Ceilometer samples. This is the preferred method of data collection. If you are working on some OpenStack related project and are using the Oslo library, you are kindly invited to come and talk to one of the project members to learn how you could quickly add instrumentation for your project.
- Polling agents, which is the less preferred method, will poll some API or other tool to collect information at a regular interval. The polling approach is less preferred due to the load it can impose on the API services.
The first method is supported by the ceilometer-notification agent, which monitors the message queues for notifications. Polling agents can be configured either to poll the local hypervisor or remote APIs (public REST APIs exposed by services and host-level SNMP/IPMI daemons).
Notification Agents: Listening for data¶
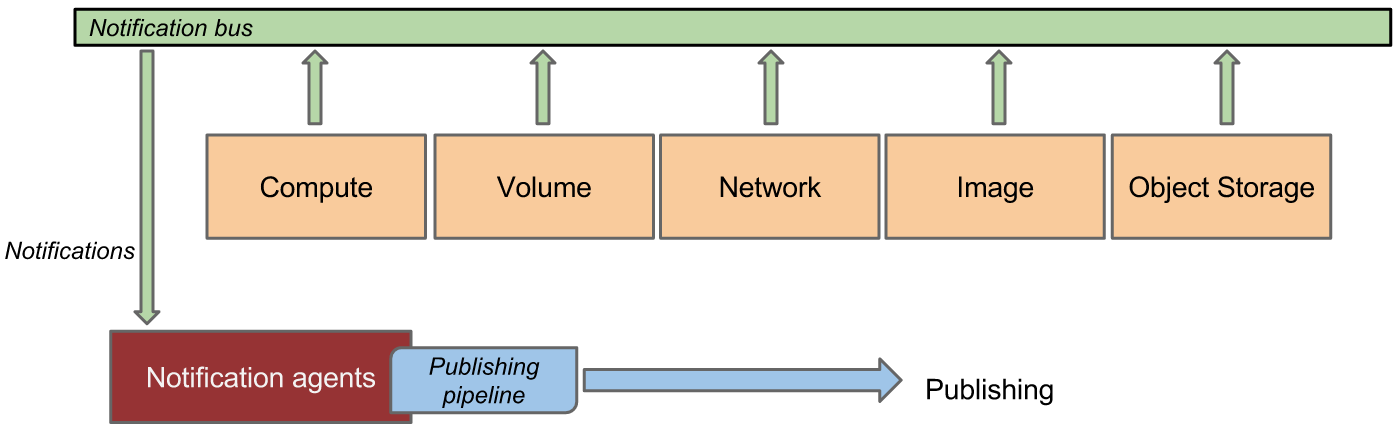
Notification agents consuming messages from services.
The heart of the system is the notification daemon (agent-notification) which monitors the message bus for data being provided by other OpenStack components such as Nova, Glance, Cinder, Neutron, Swift, Keystone, and Heat, as well as Ceilometer internal communication.
The notification daemon loads one or more listener plugins, using the namespace ceilometer.notification. Each plugin can listen to any topics, but by default it will listen to notifications.info. The listeners grab messages off the defined topics and redistributes them to the appropriate plugins(endpoints) to be processed into Events and Samples.
Sample-oriented plugins provide a method to list the event types they’re interested in and a callback for processing messages accordingly. The registered name of the callback is used to enable or disable it using the pipeline of the notification daemon. The incoming messages are filtered based on their event type value before being passed to the callback so the plugin only receives events it has expressed an interest in seeing. For example, a callback asking for compute.instance.create.end events under ceilometer.compute.notifications would be invoked for those notification events on the nova exchange using the notifications.info topic. Event matching can also work using wildcards e.g. compute.instance.*.
Polling Agents: Asking for data¶

Polling agents querying services for data.
Polling for compute resources is handled by a polling agent running on the compute node (where communication with the hypervisor is more efficient), often referred to as the compute-agent. Polling via service APIs for non-compute resources is handled by an agent running on a cloud controller node, often referred to the central-agent. A single agent can fulfill both roles in an all-in-one deployment. Conversely, multiple instances of an agent may be deployed, in which case the workload is shared. The polling agent daemon is configured to run one or more pollster plugins using either the ceilometer.poll.compute and/or ceilometer.poll.central namespaces.
The agents periodically ask each pollster for instances of Sample objects. The frequency of polling is controlled via the pipeline configuration. See Pipelines for details. The agent framework then passes the samples to the notification agent for processing.
Processing the data¶
Pipeline Manager¶
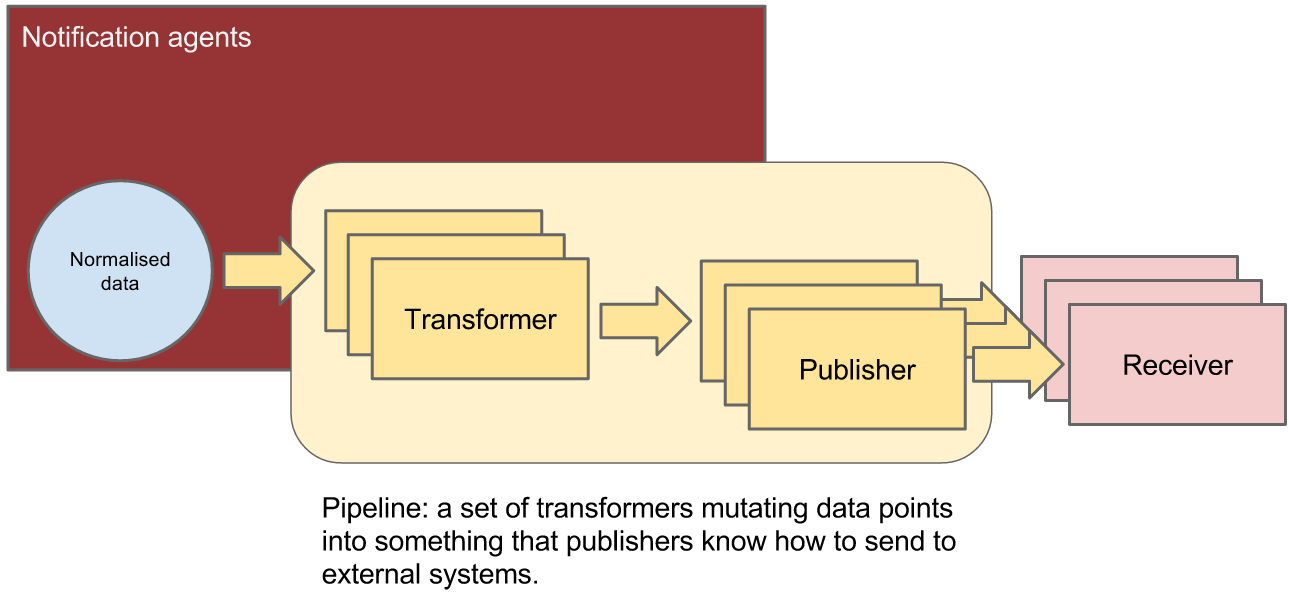
The assembly of components making the Ceilometer pipeline.
Ceilometer offers the ability to take data gathered by the agents, manipulate it, and publish it in various combinations via multiple pipelines. This functionality is handled by the notification agents.
Transforming the data¶
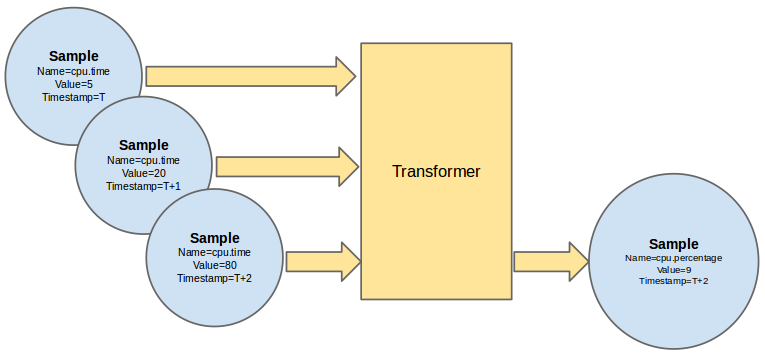
Example of aggregation of multiple cpu time usage samples in a single cpu percentage sample.
The data gathered from the polling and notifications agents contains a wealth of data and if combined with historical or temporal context, can be used to derive even more data. Ceilometer offers various transformers which can be used to manipulate data in the pipeline.
Publishing the data¶
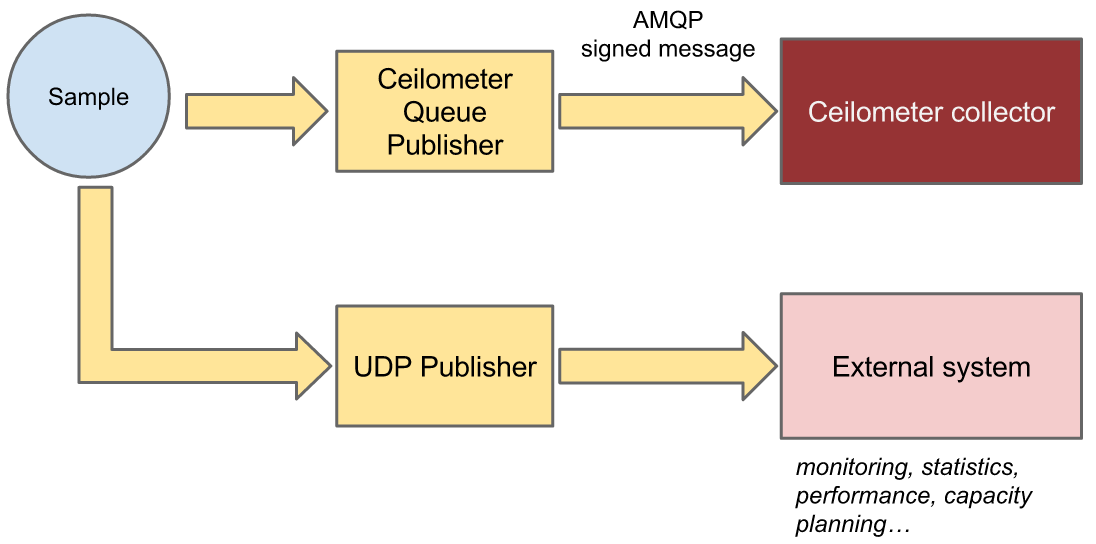
This figure shows how a sample can be published to multiple destinations.
Currently, processed data can be published using 5 different transports:
- direct, which publishes samples to a configured dispatcher directly, default is database dispatcher;
- notifier, a notification based publisher which pushes samples to a message queue which can be consumed by the collector or an external system;
- udp, which publishes samples using UDP packets;
- http, which targets a REST interface;
- kafka, which publishes data to a Kafka message queue to be consumed by any system that supports Kafka.
Storing the data¶
Collector Service¶
The collector daemon gathers the processed event and metering data captured by the notification and polling agents. It validates the incoming data and (if the signature is valid) then writes the messages to a declared target: database, file, gnocchi or http.
More details on database and Gnocchi targets can be found in the Choosing a database backend guide.
Accessing the data¶
API Service¶
If the collected data from polling and notification agents are stored in Ceilometer’s database(s) (see the section Choosing a database backend), a REST API is available to access the collected data rather than by accessing the underlying database directly.

This is a representation of how to access data stored by Ceilometer
Moreover, end users can also send their own application specific data into the database through the REST API for a various set of use cases.